X-Technologien
Table of Contents
- XML
- X-Technologien Überblick
- Das XQuery and XPath Data Model (XDM)
- XPath
- XSLT
- Starten von Transformationen und Tests
- Beispiele
- Übungen
- Spezifikationen
X-Technologien Überblick
XPath
Die bekannteste und wichtigste Funktion von XPath ist die navigation innerhalb einer XML-Struktur. Sprache zur Adressierung und Verarbeitung von Werten, die dem XDM entsprechen. XPath ist eine “hosted language” in XSLT. Dort wird sie u. A. verwendet um Knoten zu Adressieren (in match und select-Attributen), aber auch, um Sequenzen von Werten zu erzeugen (z. B. in Variablendefinitionen).
XQuery
XQuery ist eine Abfragesprache für XML-Datenbanken. Die Sprache ist ein Superset von XPath, d. h. jeder gültige XPath-Ausdruck ist auch ein gültiger XQery-Ausdruck – aber nicht umgekehrt. Sie dient nicht nur dazu, Knoten(mengen) auszuwählen, sondern auch dazu Daten zu aggregieren, Reports (vorzugsweise wieder in XML) zu erstellen, etc.
XSLT
Die “XSL Transformations (XSLT)” dienen zur Transformation von XML, vorzugsweise in anderes XML. Die Sprache ist deklarativ und streng funktional. Diese Eigenschaften machen eignen sie besonders für komplexe Anwendungsfälle: Der funktionale Aufbau macht es unwahrscheinlicher, dass, wenn man an einem Schräubchen dreht, sich andere Schrauben unbemerkt mitdrehen. Ihre Syntax ist selbst wieder XML. Diese, Homoikonizität genannte, Eigenschaft macht es möglich XSLT zu XSLT zu transformieren. Das passiert in einer recht simplen Form auch tatsächlich bei den Normalisierungen für Alma.
Das XQuery and XPath Data Model (XDM)
XPath operiert nicht anhand der textuellen Struktur eines XML-Dokuments, sondern anhand des abstrakten Baumes, der durch Parsen von XML-Dokumenten oder -Fragmenten instanziiert wird.
Wichtige Begriffe
Items
Ein item ist entweder atomarer Wert, ein Knoten oder eine Funktion.
Atomare Werte
Atomare Werte sind Werte, die einem “atomaren Typ” angehören. Das sind z. B.:
- xs:untypedAtomic
- Fallback für z. B. Attributwerte, wenn gegen kein Schema geprüft wird. D. h. der Prozessor sieht nur den Textinhalt “2002-10-10T12:00:00-05:00Z” und weiß nicht, dass er ihn z. B. als Datum (
xs:dateTime) interpretieren soll. - xs:numeric
- Vereinigungstyp aus
xs:double,xs:floatundxs:decimal. Also Zahlen. - xs:string
- Eine Zeichenkette
- xs:boolean
- Ein Wahrheitswert. D. h.
trueoderfalse - …
Knoten
Es gibt sieben Arten von Knoten:
Jeder Knoten hat eine eindeutige Identität die ihn von allen anderen Knoten im Baum unterscheidet, auch wenn die textuelle Repräsentation von zwei Knoten gleich aussehen mag.
Im folgenden Beispiel gibt es zwei mal das Attribut tag="500". Es handelt sich dabei aber um zwei eindeutig unterscheidbare Knoten im Datenmodell.
<record> <datafield tag="500" ind1=" " ind2=" "> <subfield code="a">Erste Anmerkung</subfield> </datafield> <datafield tag="500" ind1=" " ind2=" "> <subfield code="a">Zweite Anmerkung</subfield> </datafield> </record>
Der Attributwert 500 ist ein atomicValue. Dieser hat keine Identität. D. h. der Wert 500 ist in beiden Fällen derselbe.
Funktionen
Siehe XPath – Funktionen
Die Sequenz
Jede valide Instanz des Datenmodells ist eine Sequenz. Eine Sequenz ist eine geordnete Sammlung von null oder mehreren items. Jedes Item in einer Sequenz hat eine stabile Position (ermittelbar durch position()). Das erste Item in einer Sequenz ist auf Position 1 (nicht 0, wie in vielen anderen Programmiersprachen).
Eine Sequenz kann nicht in einer Sequenz enthalten sein. D. h. eine Kombination aus Sequenzen wird “geplättet”. D. h. (1, (2, 3), (), (), 4) wird zu (1, 2, 3, 4)
Ein einzelnes (“singleton”) item wird als eine Sequenz modelliert, die genau dieses eine item enthält.
Document Order
Alle Knoten eines Dokuments haben eine absolute Reihenfolge. Diese Reihenfolge ist stabil und ändert sich nicht während einer Abfrage oder Transformation. Informell ist die Dokumentreihenfolge definiert als die Reihenfolge, in der die Knoten in einer XML-Serialisierung eines Dokuments erscheinen.
XPath
Pfadausdrücke
Pfadausdrücke selektieren eine Sequenz von Items und geben diese zurück. Im Kontext der Programmierung heißt das, dass man nicht nur eine Liste der gefundenen Dinge bekommt, sondern tatsächlich die Dinge selbst, um etwas mit ihnen tun zu können.
Einzelne Schritte in einem Pfadausdruck werden durch / (den path operator) getrennt. Steht ein / am Anfang eines Ausdrucks, selektiert es den Wurzelknoten.
Nach dem Pfad-Operator / kommt ein “Schritt”. Ein solcher Schritt besteht aus der Achse, die die “Bewegungsrichtung” für den Schritt definiert und einem Knotentest. Ein Knotentest selektiert Knoten nach ihrer Art, ihrem Namen oder ihrem Typ.
Achsen
Prädikate
Die Sequenz, die ein Schritt zurückgibt, kann durch Prädikate weiter gefiltert werden. Ein Prädikat wendet eine Prüfung auf jeden Knoten der Sequenz an und entfernt alle, bei denen die Prüfung false ergibt. Daher spricht man auch von Filterausdrücken.
Besipiel:
/collection/record/datafield[@tag="245"]
/collection/record erzeugt eine Sequenz mit allen record-Elementen. /datafield holt wiederum aus all diesen Records alle datafields. Das Prädikat [@tag="245"] lässt aber nur die durch, die ein Attribut tag mit dem Wert 245 haben.
Man kann auch mehrere Prädikate angeben. Diese werden von links nach rechts abgearbeitet:
/collection/record/datafield[@tag="245"][@ind2!="0"]
Hier bekommen wir alle Titelfelder mit zu übergehenden Zeichen am Anfang. Man sieht hier auch, dass es zweckdienlich ist, zuerst die Prädikate anzugeben, die mehr ausfiltern (also kürzere Sequenzen durchlassen). Hätte man die Prädikate oben vertauscht würden zuerst alle datafield selektiert, die keinen zweiten Indikator “0” haben. Diese große Menge wiederum würde erst auf das Vorhandensein von tag="245" geprüft, während in der Version oben nur noch wenige elemente überhaupt die zweite Prüfung erreichen. Das kann gravierende Auswirkungen auf die Laufzeit einer Abfrage haben!
Vergleichsausdrücke
Xpath kennt zwei Arten von Vergleichen: Value comparisons und general comparisons
Value comparisons
Das ist, was man erwartet, wenn man an Vergleiche denkt. Hier werden zwei Werte verglichen, also z. B. zwei Strings, zwei Ganzzahlen, etc. Wenn auf einer Seite des Operators mehr als ein Item ist, führt das zu einem Fehler.
Die Operatoren sind:
| Operator | Vergleich |
|---|---|
eq |
gleich |
ne |
ungleich |
gt |
größer |
ge |
größer gleich |
lt |
kleiner |
le |
kleiner gleich |
Ergebnis des Vergleichs zweier Operanden ist ein Wahrheitswert. D. h. 2 eq 2 ist true 2 gt 2 ist false.
General comparisons
Bei general comparisons tritt wieder die Sequenz als Bestimmendes Merkmal des Datenmodells zutage.
Hier werden alle Werte der Sequenz auf der linken Seite mit allen Werten auf der rechten Seite verglichen. Wenn einer dieser Vergleiche erfolgreich ist, liefert die general comparison true zurück.
Die Operatoren:
| Operator | Vergleich |
|---|---|
= |
gleich |
!= |
ungleich |
> |
größer |
>= |
größer gleich |
< |
kleiner |
<= |
kleiner gleich |
Das ist sehr oft sehr praktisch. Z. B. kann man prüfen, ob eine Sequenz einen bestimmten Wert enthält: 2 = (1, 2, 3, 4) ist true. Es ist aber mit Vorsicht zu genießen, weil 2 != (1, 2, 3, 4) ist auch true. Warum?
Logische Ausdrücke
Für logische Operationen gibt es in XPath die Operatoren and und or sowie die Funktion not().
Diese Operatoren tun das, was man erwartet: Sie nehmen zwei Wahrheitswerte und geben einen Wahrheitswert zurück und folgen den Regeln der zweiwertigen Aussagen- oder Prädikatenlogik. Der Bequemlichkeit halber die üblichen Wahrheitstafeln:
Für or:
| OR | true | false |
| true | true | true |
| false | true | false |
Für and:
| AND | true | false |
| true | true | false |
| false | false | false |
Und not()
| NOT | true | false |
| false | true |
Das heißt trivialerweise das true() and true() true ergibt, etc. Natürlich werden üblicherweise keine nackten Wahrheitswerte sondern quasi Aussagen überprüft, wie z. B. hier:
let $number1 := 3 let $number2 := 7 let $string1 := "ogopogo" return $number1 gt $number2 or string-length($string1) eq $number2 and string-length($string1) mod $number1 eq 1
true
Effective Boolean Value
Die Dinge, die mit logischen Operatoren verbunden sind, können nicht nur Wahrheitswerte sein. Oft verwendet man den “effective boolean value” (EBV). Ein sehr übliches Beispiel ist ein Prädikat, das auf das Vorhandensein eines Elements prüft, wie datafield[subfield]. Wir haben ja oben gelesen, dass ein Prädikat alle items einer Sequenz durchlässt, bei denen die Bedingung im Prädikat zutrifft, also wahr ist. Nun ist das Ergebnis von subfield nicht true oder false sondern eine (möglicherweise leere) Sequenz aller Subfelder. Trotzdem funktioniert es. Warum? Es gibt Regeln, nach denen ein effektiver Wahrheitswert gebildet wird:
- leere Sequenz →
false - eine Sequenz deren erstes Item ein Knoten (
node) ist →true - bei Einzelwerten der Typen
xs:string,xs:anyURI,xs:untypedAtomicund davon abgeleiteten Typen- wenn der Wert die Länge
0hat →false - sonst:
true
- wenn der Wert die Länge
- bei Einzelwerten eines numerischen Typs (also Zahlen)
- wenn der numerische Wert
NaNoder0ist →false - sonst:
true
- wenn der numerische Wert
- In allen anderen Fällen wirft der Prozessor einen Fehler.
Im Beispiel oben (datafield[subfield]) wird einer der Fälle 1. oder 2. zutreffen.
Funktionen
XPath und XQuery (und damit an bestimmten Stellen auch XSLT) haben eine umfangreiche Sammlung an Funktionen: https://www.w3.org/TR/xpath-functions-31/
Diese sind hilfreich sowohl in Prädikaten (um eine Ergebnissequenz zu filtern) als auch zum Erstellen von modifizierten Ergebnissequenzen.
Beispiele
Einsatz in Prädikaten:
/persons/person/name[upper-case(.) eq "ELVIS"]
Findet alle Personen mit Namen “Elvis”, egal ob sie groß oder klein geschrieben sind. Die Funktion gibt immer den Eingabestring in Großbuchstaben zurück und wir prüfen gegen den String “ELVIS”.
/persons/person/name[upper-case(.) eq "Elvis"]
Was bekommen wir hier zurück?
Zur Konstruktion eines neuen Wertes:
<xsl:template match="datafield[@tag='245']/subfield[@code='a']"> <subfield code="a"> <xsl:value-of select="replace(., 'foo', 'bar')" /> </subfield> </xsl:template>
Dieses Template ändert den Wert von 245$$a, indem es die Zeichenkette foo gegen bar ersetzt .
Beispielabfragen
/collection/record => count()
0
XSLT
Verarbeitungsmodell
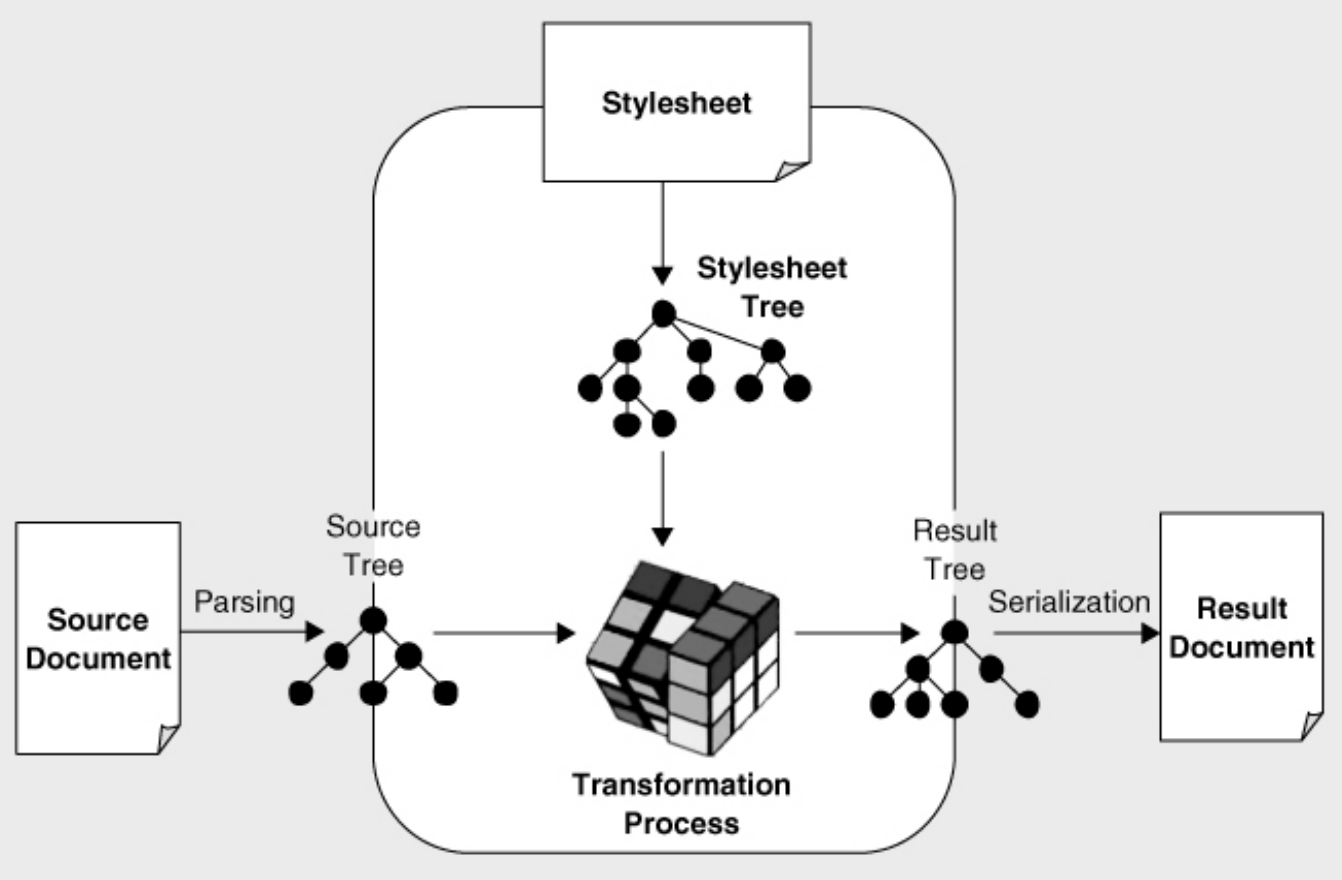
Figure 1: Kay 2008, p. 45
Ablauf einer Transformation
Danke ChatGPT!
Eingabedaten
- Eingabe besteht aus:
- Dem Quell-XML-Dokument.
- Dem XSLT-Stylesheet (ebenfalls XML-Struktur).
- Beides wird geparst und in den Speicher geladen
Grundidee
- XSLT folgt einem deklarativen Ansatz:
- Es wird nicht Schritt-für-Schritt programmiert, sondern Regeln (Templates) definieren, wie Knoten im Eingabe-XML in Ausgabestrukturen transformiert werden.
- Die Verarbeitung basiert auf dem Match-and-Apply-Prinzip.
- “Wenn du diesen Input siehst, generiere Output, der so und so aussieht.”
Ablauf im Detail
- Parsing
- Das Quell-XML und das XSLT-Stylesheet werden beide zu XML-Baumstrukturen
- Initiales Template
- Optional kann man bestimmen, welches Template als erstes ausgeführt werden soll
- Template-Matching
- Der Prozessor sucht zu jedem aktuellen Eingabeknoten das am beste passende
Template (
<xsl:template match="...">). - Falls kein passendes Template existiert, greift die eingebaute Standardregel:
- Für Texte: Ausgabe des Textinhalts.
- Für Elemente: rekursives Anwenden auf Kindknoten.
- Der Prozessor sucht zu jedem aktuellen Eingabeknoten das am beste passende
Template (
- Anweisungen im Template
- Wichtige Deklarationen:
xsl:apply-templates→ Verzweigt zu anderen Knotenxsl:sequence→ Schreibt eine Sequenz von items in die Ausgabexsl:value-of→ Gibt Textwert eines Knotens ausxsl:for-each→ Iteration über Knotenmengenxsl:if/xsl:choose→ Bedingte Verarbeitung
- Wichtige Deklarationen:
- Rekursive Verarbeitung
xsl:apply-templateslöst wieder Template-Matching aus.- Dadurch kann der gesamte Eingabebaum Schritt für Schritt transformiert werden.
- Ausgabe
- Der Ausgabebaum wird “serialisiert” (nicht notwendigerweise, aber in unseren Fällen immer)
- XSLT erzeugt standardmäßig XML oder Text,
aber je nach
xsl:outputauch HTML oder andere Textformate.
Wichtige Eigenschaften
- Baumorientiert: XSLT arbeitet immer mit Knotenbäumen, nicht mit Zeichenketten.
- Deklarativ: Man beschreibt was passieren soll, nicht wie.
- Regelgesteuert: Verarbeitung läuft über Template-Matching, nicht lineare Befehlsfolgen.
- Deterministisch: Bei gleichen Eingaben und Stylesheets immer gleiche Ausgaben.
Beispielablauf
Gegeben:
<root> <item>A</item> <item>B</item> </root>
Stylesheet:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <html><body><xsl:apply-templates/></body></html> </xsl:template> <xsl:template match="item"> <p><xsl:value-of select="."/></p> </xsl:template> </xsl:stylesheet>
Ablauf:
- Start: Template
/→ Erzeugt<html><body>…</body></html>. xsl:apply-templates→ Findet<item>-Elemente.- Für jedes
<item>: passendes Template erzeugt<p>Inhalt</p>. Ausgabe:
<html><body><p>A</p><p>B</p></body></html>
Ablaufdiagramm
Quell-XML │ ▼ Parsen → XML-Baum │ │ + XSLT-Stylesheet → Parsen → Template-Baum ▼ Start-Template (match="/") │ ▼ Template-Matching + Ausführung (apply-templates, value-of, etc.) │ ▼ Ausgabebaum │ ▼ Serialisierung → Endausgabe (XML / HTML / Text)
Wichtige Deklarationen und Anweisungen
xsl:template
xsl:template ist die wohl wichtigste Deklaration in XSLT. Das <xsl:template> element muss entweder ein match und/oder ein name-Attribut haben.
- match-templates
xsl:template-Deklarationen mit einemmatch-Attribute nennt man gemeinhin “Match-Template” oder “Matching-Template”. Der Wert von@matchenthält ein pattern. Wenn ein Knoten dieses Pattern “matcht”, also das Pattern auf einen Knoten zutrifft, wird der Sequenz-Konstruktor (also der Inhalt desxsl:template-Elements) evaluiert und die sich daraus ergebende Sequenz in den Ausgabebaum geschrieben. - named templates
Wenn ein Template ein
name-Attribut hat, kann es von anderen Templates aus mit derxsl:call-template name="name-des-templates" />-Anweisung aufgerufen werden. Das Template wird dann im aufrufenden Kontext ausgeführt:<xsl:template match="record"> <xsl:call-template name="copy-current-context-node" /> </xsl:template> <xsl:template name="copy-current-context-node"> <xsl:sequence select="." /> </xsl:template>
Im obigen Beispiel wird der Kontexknoten des aufrufenden Templates (also der gematchte
record) in den Ausgebebaum kopiert.
Entscheidungen treffen: xsl:if und xsl:choose
Manche Anweisungen sollen nur dann ausgeführt werden, wenn bestimmte Bedingungen gegeben sind. Hier der Link zur Spezifikation:Contitional Processing
- xsl:if
Die Anweisung
xsl:ifhat ein verpflichtendes Attribut@test. Ist der effektive Wahrheitswert des Ausdrucks in diesem Attribut wahr, wird der inxsl:ifenthaltene Sequenz-Konstruktor evaluiert und die daraus resultierende Sequenz wird zurückgegeben. Andernfalls wird der Sequenz-Konstruktor nicht evaluiert und der Rückgabewert ist die leere Sequenz.Beispiel:
<xsl:template match="record"> <!-- ... --> <xsl:if test="not(controlfield[@tag='007'])"> <controlfield tag="007">tu</controlfield> </xsl:if> <!-- ... --> </xsl:template>
- xsl:choose
Sollen unter verschiedenen Bedingungen verschiedene Dinge passieren, ist die
xsl:choose-Anweisung das Werkzeug der Wahl. Dasxsl:choose-Element muss mindestens einxsl:whenelement enthalten.xsl:whenhat das verpflichtende Attribut@test. Ist der effektive Wahrheitswert des Ausdrucks in diesem Attribut wahr, wird der enthaltene Sequenz-Konstruktor evaluiert und die daraus resultierende Sequenz wird zurückgegeben. Ist er falsch, wird die nächstexsl:when-Anweisung ausgeführt.Das Ergebnis von
xsl:chooseis das Ergebnis der ersten zutreffendenxsl:when-Anweisung. Nach der ersten zutreffendenxsl:choose-Anweisung werden keine weiteren Anweisungen verarbeitet.Trifft keines der
@test-Attribute zu, wird der Sequenz-Konstruktor in derxsl:otherwise-Anweisung evaluiert. Trifft kein@test-Attribut zu und es gibt keinxsl:otherwise, ist das Ergebnis vonxsl:choosedie leere Sequenz.Beispiel:
<xsl:choose> <xsl:when test="contains(basket, 'orange')">juice</xsl:when> <xsl:when test="contains(basket, 'apple')">pie</xsl:when> <xsl:otherwise>grub</xsl:otherwise> </xsl:choose>
- Wenn
basketim obigen Beisiel"kiwi orange apple banana"ist, ist das Ergebnis"juice". - Wenn
basketim obigen Beisiel"kiwi lemon apple banana "ist, ist das Ergebnis"pie". - Wenn
basketim obigen Beisiel"kiwi lemon pear banana "ist, ist das Ergebnis"grub".
- Wenn
xsl:copy-of und xsl:sequence
xsl:copy-of und xsl:sequence geben eine Sequenz an Knoten zurück, die durch das @select-Attribut definiert werden. In xsl:sequence kann man statt dem @select auch einen Sequenz-Kostruktur verwenden.
Der Effekt von beiden Anweisungen ist den meisten Fällen der gleiche. xsl:copy-of erstellt allerdings eine tiefe Kopie der selektierten Knoten. xsl:sequence gibt auch vorhandene Knoten zurück, was effizienter sein kann.
Starten von Transformationen und Tests
Eine Transformation starten
Diese Anleitung geht davon aus, dass es in $PATH das Script saxon-xslt gibt und dieses ausführbar ist. Dieses wird folgendermaßen aufgerufen:
saxon-xslt SOURCE-FILE XSLT-STYLESHEET
Damit wird SOURCE-FILE entsprechend XSLT-STYLESHEET transformiert und das Ergebnis auf der Konsole (auf stdout) ausgegeben. Will man das Ergebnis in einer Datei speichern, nutzt man die output redirection der shell:
saxon-xslt marc_records.xml convert.xsl > marc_records_converted.xml
Tests laufen lassen
Diese Anleitung geht davon aus, dass es in $PATH das Script xspec.sh gibt und dieses ausführbar ist. Der Aufruf ist simpel:
xspec.sh XSPEC-FILE
Das heißt, wenn die Tests in der Datei tests/tests.xspec wohnen:
xspec.sh tests/test.xspec
XSpec gibt die Ergebnisse der Tests auf der Konsole aus. Ein detaillierter Testbericht ist als HTML-Datei verfügbar. Wo diese zu finden ist, steht am Ende der Konsolenausgabe.
Beispiele
Text in Subfeld ändern
Wir wollen Zahlen am Ende von 9707#$$d entfernen.
<xsl:template match="datafield[@tag='970'] [@ind1='7'] [@ind2=' '] /subfield[@code='d'][matches(., '^IV-SCAN[0-9]+$')]"> <subfield code="d">{replace(., "[0-9]+$", "")}</subfield> </xsl:template>
Dieses Template matcht auf Subfelder d in 9707#, wenn diese mit dem Muster ^IV-SCAN[0-9]+$ entsprechen. D. h. wenn sie mit IV-SCAN beginnen, direkt gefolgt von einer oder mehreren Ziffern. Danach kommt nichts mehr.
Aus
<datafield tag="970" ind1="7" ind2=" "> <subfield code="d">IV-SCAN9</subfield> <subfield code="d">IV-SCAN88</subfield> <subfield code="d">Nicht IV-SCAN1</subfield> <subfield code="d">IV-SCAN42LÖSCHTMANNICHT</subfield> <subfield code="a">Testfeld</subfield> </datafield>
wird dann
<?xml version="1.0"?> <datafield tag="970" ind1="7" ind2=" "> <subfield code="d">IV-SCAN</subfield> <subfield code="d">IV-SCAN</subfield> <subfield code="d">Nicht IV-SCAN1</subfield> <subfield code="d">IV-SCAN42LÖSCHTMANNICHT</subfield> <subfield code="a">Testfeld</subfield> </datafield>
337 aus 338 generieren
Drools-Implementierung: https://gitlab.obvsg.at/AlmaConfig/droolsConfig/-/blob/master/rules/normalizationRules/KATA/src/KATA-004-a33Xb.src?ref_type=heads
Also so eine Regel für jeden möglichen Code in 338##$$b (11 Stück):
rule "KATA-004-a33Xb: generate 337 b.s from 338 b.s*" /* name: KATA-004-a33Xb fields: 337 definition: generate 337 b.s from 338 b.s* note: */ when exists "338.b.s*" and not exists "337.b.s" then addField "337.b.s" end
XSLT-Umsetzung:
<xsl:template match="datafield[@tag='338']/subfield[@code='b']"> <!-- Das 338 $$b selbst übernehmen (sonst verschwindet es) --> <xsl:sequence select="." /> <!-- Falls es keine 337 gibt, erzeuge eine mit dem ersten Zeichen von 338 $$b in $$b. --> <xsl:if test="not(../../datafield[@tag='337'])"> <datafield tag="337" ind1=" " ind2=" "> <subfield code="b">{substring(., 1, 1)}</subfield> </datafield> </xsl:if> </xsl:template>
Bindestriche aus ISBN in 020 entfernen
Drools-Regel:
rule "KATA-014-ISBN: delete hyphens in 020 SF-a" /* name: KATA-014-ISBN fields: 020 definition: Entferne die Bindestriche aus ISBNs in 020, 77X, 78X. note: */ when exists "020.a" or exists "77*.z" or exists "78*.z" then replaceContents "020.a.-" with "" replaceContents "77*.z.-" with "" replaceContents "78*.z.-" with "" end
XSLT
<xsl:template match="datafield[@tag=('020', '773', 'TBD')]/subfield[@code=('a', 'z')]"> <subfield code="{@code}">{replace(., "-", "")}</subfield> </xsl:template>
Feld 655
Setze den zweiten Indikator auf ’7’, wenn es ein nicht-leeres $$2 gibt.
rule "KATA-074-655ind2: change second indicator to 7, if exists Sf2" /* name: KATA-074-655ind2 fields: 655 definition: Ändere `655 @ind2` auf `7` wenn es SF2 gibt. note: */ when exists "655.2" then changeFirstIndicator "655" to " " changeSecondIndicator "655" to "7" if (exists "655.2") end
XSLT
<xsl:template match="datafield[@tag='655'][subfield[@code='2']/text()]/@ind2"> <xsl:attribute name="ind2">7</xsl:attribute> </xsl:template>
Übungen
ex01: Felder löschen
ex01_01: Lösche das Feld 998
ex01_02: Lösche 77308$$9
ex02: Felder nach inhaltlichen Kriterien löschen
ex02_01:
Wir wollen alle Felder 500 löschen, die in $$a den Text foo enthalten.
ex02_02:
Wir wollen alle Felder 500 löschen, die in $$a den Text foo, aber nicht den Text bar enthalten.
ex02_03:
Wir wollen alle Felder 500 löschen, die in $$a den Text foo direkt gefolgt von einer beliebig langen Zahl enthalten. Also foo1, foo667, foo00000000000000001.
ex03: Felder umbenennen
ex03_02: Hochschulschriftenvermerk von 500## nach 502## verschieben
ex04: Feldinhalte ändern
ex04_01: Falsche GND-Nummer in 655
Eine Zeitlang war in der CV-Liste für den Term “Backbuch” eine falsche GND-ID, nämlich (DE-588)7502992-3. Richtig wäre (DE-588)1071926306.
- Stylesheet: exercises/ex04/ex04_01.xsl
- Tests: exercises/ex04/ex04_01.xspec
Im Folgenden werden drei mögliche Lösungen vorgestellt. Sie bringen das gleiche Ergebnis. Welche man bevorzugt, ist eine Frage des Stils. Man sollte eine Lösung wählen, von der man glaubt, dass sie die Intention gut darstellt, wenn man den Code später wieder liest.
xsl:choose
Das Template hier matcht auf Subfeld 0 und erst in der Template-Rule wird via
xsl:chooseentschieden, ob die Nummer falsch ist. Wenn nicht, wird das Subfeld unverändert in die Ausgabe geschrieben:<xsl:template match="datafield[@tag='655'] [subfield[@code='a'][.='Backbuch']] /subfield[@code='0']"> <xsl:choose> <xsl:when test="not(.='(DE-588)1071926306')"> <subfield code="0">(DE-588)1071926306</subfield> </xsl:when> <xsl:otherwise> <xsl:sequence select="." /> </xsl:otherwise> </xsl:choose> </xsl:template>
Sehr explizit, aber auch länglich.
- Im
matchauf die falsche Nummer prüfen
Hier wird gleich im
machauf die falsche Nummer geprüft. Daher ist es nicht notwendig, sich um Felder mit der richtigen Nummer zu kümmern – diese werden nicht gematcht und von diesem Template dementsprechend nicht betrachtet.Durch diese Vorgehensweise ist in der Template-Rule keinerlei Prüfung notwendig und daher enthält sie nur das literale Ausgabeelement.
<xsl:template match="datafield[@tag='655'] subfield[@code='a'][.='Backbuch']] /subfield[@code='0'] [.='(DE-588)7502992-3']"> <subfield code="0">(DE-588)1071926306</subfield> </xsl:template>
Kurz und knackig. Die Logik liegt im
match, was bei komplexeren Sachverhalten unübersichtlich werden kann. - Im
matchauf die falsche Nummer prüfen und direkt den Textknoten bearbeiten
Die Prüfung ist gleich wie in der vorigen Lösung, nur dass hier nicht auf das Subfeld sondern direkt auf den Textknoten gematcht wird.
Der Text wird mit
xsl:textgeneriert. Würde man in direkt insxsl:template-Element schrieben, würde er auch Zeilenumbrüche etc. enthalten.<xsl:template match="datafield[@tag='655'] [subfield[@code='a'][.='Backbuch']] /subfield[@code='0'] [.='(DE-588)7502992-3'] /text()"> <xsl:text>(DE-588)1071926306</xsl:text> </xsl:template>
Im Prinzip wie die vorige Lösung, nur noch gezielter. Ob die Absicht hier so gut zu erkennen ist, weiß ich nicht.
ex05: LDR/19 je nach Gegebenheiten setzen
ex06: 773 bearbeiten
ex07: Ein ganzer Datensatz
Wir haben eine E-Book Lieferung. Bei den enthaltenen Datensätzen ist folgendes zu tun:
LDR/18aufcsetzen008008/07-10mit dem Jahr aus264befüllen008/23auf “o” setzen
041aus008/35-37generieren245- Nichtsortierzeichen einfügen
336,337,338SFa und SF2 entfernen260durch264ersetzen- ISBD-Interpunktion entfernen
9XXlöschen- Output sortieren
Spezifikationen
- XPathXML Path Language (XPath) 3.1
- https://www.w3.org/TR/xpath-31/
- XDMXQuery and XPath Data Model (XDM) 3.1
- https://www.w3.org/TR/xpath-datamodel-31/
- XPath and XQuery Functions and Operators 3.1
- https://www.w3.org/TR/xpath-functions-31/
- XSL Transformations (XSLT) Version 3.0
- https://www.w3.org/TR/xslt-30/